Code Structure¶
Our test code is written in C++ and designed completely from scratch. We use type definitions, templates, template-specialization, overloading and other C++ features to provide flexibility in changing precision, testing datatypes which help vectorization and also making it easier to hide architecture dependent code. The general idea is to decompose the problem into a loop over lattice site and then for each lattice site and each direction, we:
- stream-in the relevant neighboring spinor (or block of spinors in case of multiple right hand sides) from memory
- project the 4-spinor to a 2-spinor
- read relevant gauge link and multiply it or or its hermitian adjoint with the projected spinor
- reconstruct the 4-spinor from the resulting 2-spinor and accumulate to the sum over directions
- stream-out the resulting summed vector to memory
In multi-node implementations the application step would be separated into bulk- and boundary application and the former interleaved with boundary communication.
As is common in Lattice codes we attribute a color (checkerboard) to each lattice site, depending on whether the 4-dimensional coordinates sum to an even number or an odd number. The color is also referred to as a checkerboard index (cb), or parity. In the traditional 2-coloring scheme (red-black or even-odd) each checkerboard of the lattice contains half of the total number of lattice sites. In a nearest neighbor operator such as dslash, output spinors on sites of one checkerboard color (target_cb) will need neighboring input spinors only from sites of the other checkerboard color (source_cb), and hence all the sites of a given checkerboard can be conveniently computed in parallel, with no write conflicts. Gauge fields are usually stored as the forward pointing links in the 4 forward directions. The backward pointing links at a site are the hermitian conjugates of the forward pointing links of the site's back neighbors in each direction (which will have the opposite parity from the original site). Hence even for applying Dslash to sites of only one parity, the gauge fields from both parities need to be read.
Data Primitives¶
For facilitating this workflow, we define spinor and gauge link classes (in C++-like pseudocode):
// num_sites is the number of lattice sites on a single checkerboard // color of the lattice (half the total number of lattice sites) // template<typename ST,int nspin> class CBSpinor { public: ... private: // dims are: site, color, spin. spin_container<ST[num_sites][3][nspin],nspin> data; }; template<typename GT> class CBGaugeField { public: ... private: // dims are: site, direction, color, color gauge_container<GT[num_sites][4][3][3]>; };
here, ST and GT refer to spinor-type and gauge-type respectively. Those types could be SIMD or scalar types and they do not necessarily need to be the same. The data containers can be plain arrays, e.g. for (non-portable) plain implementations, or arrays decorated with pragmas (e.g. for OpenMP 4.5 offloading) or more general data container classes such as Kokkos::Views, etc.. The member functions are adopted to the container classes used in the individual implementations. Note that this design allows us to test different performance portable frameworks/methods without having to restructure large parts of the code. The additional template parameter nspin allows us to easily define 2- and 4-spinor objects.
Wilson Operator¶
At this point in time, the dslash test code is not multi-node ready, so we will focus solely on on-node parallelism for the moment. Our goal is to achieve this by threading over lattice sites and applying SIMD/SIMT parallelism over multiple right hand sides. In theory, one could achieve vectorization for single right hand side vectors also by using an array or structure of array data layout but we will not consider this technique here. We will nevertheless compare our single right hand side performance we achieved with our performance portable implementations with those of optimized libraries which feature such improvements.
Our dslash class is implemented as follow:
template<typename GT, typename ST, typename TST, const int isign, const int target_cb>> class Dslash { public: void operator(const CBSpinor<ST,4>& s_in, const CBGaugeField<GT>& g_in_src_cb, const CBGaugeField<GT>& g_in_target_cb, CBSpinor<ST,4>& s_out) { // Threaded loop over sites parallel_for(int i=0; i<num_sites; i++){ CBThreadSpinor<TST,4> res_sum; CBThreadSpinor<TST,2> proj_res, mult_proj_res; Zero(res_sum); // go for direction -T ProjectDir3<ST,TST,isign>(s_in, proj_res,NeighborTMinus(site,target_cb)); mult_adj_u_halfspinor<GT,TST>(g_in_src_cb,proj_res,mult_proj_res,NeighborTMinus(site,target_cb),3); Recons23Dir3<TST,isign>(mult_proj_res,res_sum); // go for direction +T ProjectDir3<ST,TST,-isign>(s_in,proj_res,NeighborTPlus(site,target_cb)); mult_u_halfspinor<GT,TST>(g_in_target_cb,proj_res,mult_proj_res,site,NeighborTPlus(site,target_cb),3); Recons23Dir3<TST,-isign>(mult_proj_res, res_sum); // go for other directions: -Z, +Z, -Y, +Y, -X, +X ... } } };
Here, the type TST denotes a thread-spinor-type which belongs to the CBThreadSpinor class. It is important to make the distinction between CBSpinor and CBThreadSpinor because, depending on the performance portability framework used, this type has to be different on CPU or GPU. What we would like to achieve ultimately is displayed in the picture below:
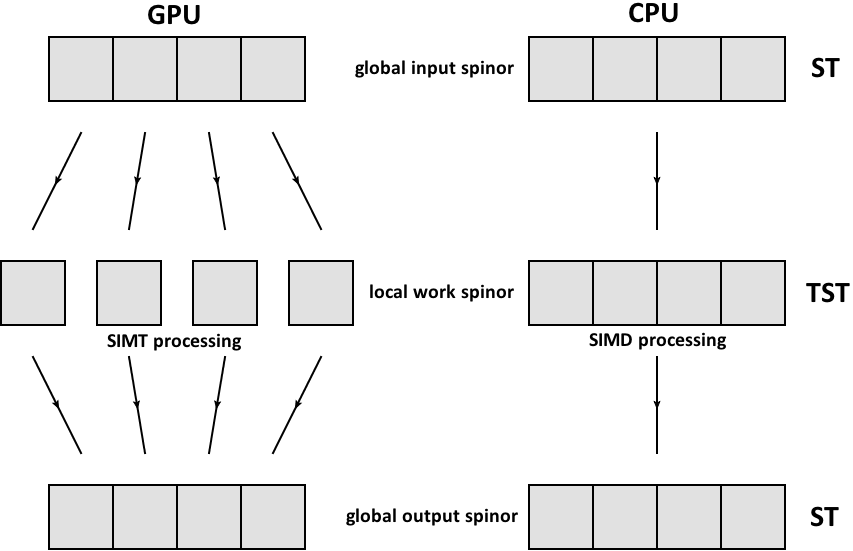
In case of the GPU (left), individual threads are each working on a single/scalar entry of the global spinor, i.e. on a single right hand side component. In case of the CPU (right), each thread is working on a chunk of right hand sites, ideally using its vector units. In both cases, the input and output spinor datatype is the same and the work spinor type is optimized for the targeted architecture.
Note that, similar to the data classes discussed above, this skeleton-dslash allows us to specialize the Wilson operator for a variety of performance portable frameworks. Additionally, if we need more architectural specialization than the various frameworks could offer, this can be implemented cleanly by operator overloading and template specializations.